Best LLM for Coding: Claude 3.5, Gemini 2.0, or GPT-4o?
> A comparative analysis of Claude 3.5 Sonnet, Gemini 2.0, and GPT-4o for coding. Discover which LLM is best for your development needs, considering accuracy, speed, and context handling.
The landscape of Large Language Models (LLMs) is rapidly evolving, with new models and updates constantly being released. For developers, choosing the right LLM for coding can significantly impact productivity and efficiency. This article delves into a comparative analysis of three leading models: Claude 3.5 Sonnet, Gemini 2.0, and GPT-4o, to determine which is the best LLM for coding: Claude 3.5, Gemini 2.0, or GPT 4o? We will examine their strengths, weaknesses, and performance across various coding tasks, drawing from a range of recent evaluations and user experiences.
Understanding the Contenders: Claude 3.5, Gemini 2.0, and GPT-4o
Before diving into a detailed comparison, it's essential to understand the unique characteristics of each model. GPT-4o, the latest offering from OpenAI, is designed for speed and efficiency, aiming for more natural human-computer interactions with multimodal capabilities. Claude 3.5 Sonnet, developed by Anthropic, emphasizes safety, long-context handling, and advanced reasoning. Google's Gemini 2.0 seeks to be versatile, handling everything from creative content to complex data analysis, with a focus on multimodal processing. It is worth noting, however, that at the time of writing, Gemini 2.0 only had a smaller model available (Flash) while the larger models where being developed.
GPT-4o: Speed and Multimodal Capabilities
GPT-4o, with its 'omni' designation, represents a step towards seamless human-computer interaction. It processes and generates text, audio, and images. It boasts faster response times compared to GPT-4 Turbo and improved multilingual support, making it a versatile tool for various coding tasks. It has a 128K token context window, allowing for complex tasks, and enhanced vision capabilities.
However, GPT-4o has some drawbacks. There is limited transparency regarding the data used for training, model size, and creation techniques. Also, while it has advanced multimodal capabilities, the API currently lacks audio input support.
Claude 3.5 Sonnet: Advanced Reasoning and Long Context
Claude 3.5 Sonnet is the latest iteration from Anthropic, focusing on safety and advanced contextual reasoning. It is designed to handle long contexts and complex logic with an emphasis on ethical and safe AI assistance. It is part of the Claude 3 family, which has set new benchmarks in cognitive tasks.
User feedback suggests that Claude 3.5 Sonnet is particularly good at breaking down complex problems, explaining concepts, and fixing errors quickly. It also excels at handling long codebases and is capable of generating useful artifacts such as sequence diagrams. However, it has been noted to struggle with certain tasks, such as LaTeX rendering for mathematical expressions, and sometimes making unsafe mistakes in code.
Gemini 2.0: Versatility and Multimodality
Gemini 2.0 is Google’s attempt at a versatile AI assistant. It offers advanced features for complex tasks, including text, image, audio, and video understanding. It's designed to handle everything from creative content generation to intricate data analysis, with minimal response latency. Gemini 2.0 has a notable feature of a large context window, up to 1 million tokens, and with a waitlist for a 2 million token context window. It also has a context caching feature, which allows large files to be sent only once, improving affordability.
However, access to Gemini 2.0, particularly with the expanded context window, can be expensive, and is often limited to select developers and organizations. There have been suggestions that the improvements with Gemini 2.0 are marginal, and that the model is converging to a base level of performance.
Coding Performance: A Head-to-Head Comparison
Evaluating the coding capabilities of these models requires examining different metrics and tasks. This includes code generation, debugging, and complex problem-solving.
Code Generation Benchmarks
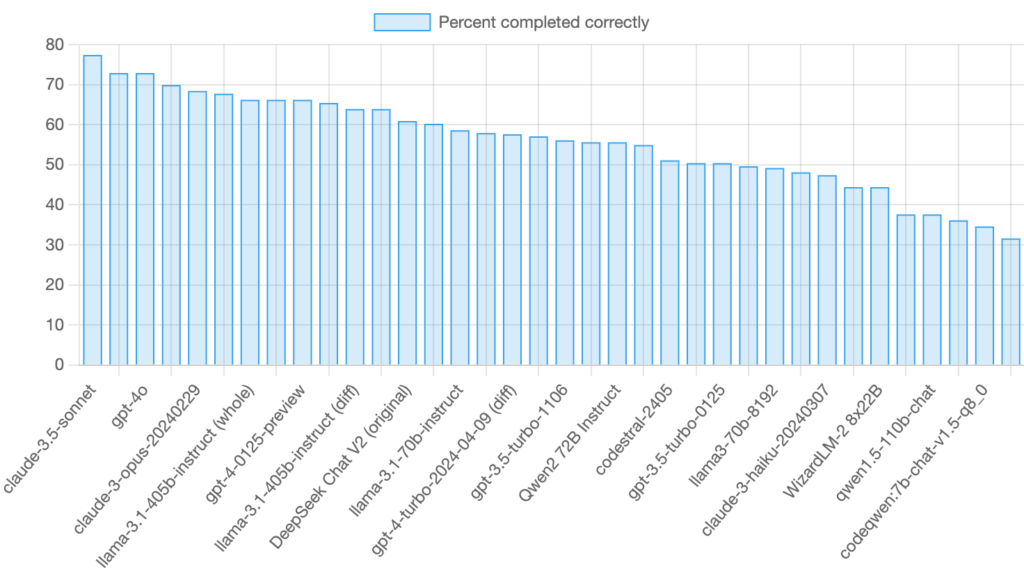
In code generation, Claude 3.5 Sonnet has shown impressive results, achieving a high completion rate on evaluated tasks. While Llama 3.1 405b is a strong open-source contender, Claude 3.5 Sonnet and GPT-4o have demonstrated superior performance. Aider's benchmarks, focusing on code editing and refactoring, show that while Llama 3.1 405b is a powerful open-source model, it is not as strong as GPT-4o and Claude 3.5 Sonnet. However, DeepSeek Coder models have surprisingly outperformed both in some coding tasks.
User Experiences and Practical Examples
User experiences on platforms like Reddit and X (formerly Twitter) vary. Some users report that Claude 3.5 Sonnet provides the best results for simple benchmarks, while others find Llama 3.1 more impressive. However, there is a general consensus that Claude 3.5 excels in tasks requiring logical reasoning and fitting pieces together into a coherent whole.
Practical examples of code generation tasks, such as creating a Python script to generate email addresses, or creating an HTML file for a personal portfolio, reveal that each model has its strengths. The choice depends on specific needs. For instance, in API query generation, the models are tasked with creating a cURL request to generate an image with the DALL-E 3 API.
Limitations and Challenges
Despite their strengths, these models are not without their limitations. GPT-4o has been noted to sometimes degrade in its smarts, and struggles with complex logical reasoning and math problems. Claude 3.5 Sonnet has shown limitations in shell scripting, often requiring manual fixes. Gemini 2.0, while versatile, has been noted to not be a significant improvement over previous models. All models can also struggle with tasks involving long contexts, with performance degrading when information is in the middle of the document.
Key Considerations for Developers
When choosing the best LLM for coding, developers should consider several key factors, including accuracy, speed, context handling, and cost.
Accuracy and Reliability
While LLMs are increasingly proficient, they can still generate erroneous or misleading outputs. Therefore, validating the output is crucial. Claude 3.5 Sonnet has been noted to be more accurate in fitting pieces together into a coherent whole, whereas GPT-4o is better suited for quick fixes.
Context Handling
Claude 3.5 Sonnet excels in maintaining context across longer interactions, making it suitable for complex projects with multiple files. GPT-4o has a respectable context window, but Claude 3.5 is generally preferred for long-context tasks.
Cost and Accessibility
GPT-4o is often seen as a cost-effective option, while Gemini 2.0 can be expensive, especially with expanded context windows. Llama 3.1 as an open-source model, is available on various platforms with varying prices. Claude 3.5 Sonnet falls in between, appealing to those who need superior long-term contextual performance but may not need the multimodal capabilities of GPT-4o.
Ethical Considerations
Claude 3.5 Sonnet emphasizes safe and responsible AI assistance, making it a preferred choice for enterprises concerned with code integrity and safety. GPT-4o and Gemini 2.0 also focus on ethical AI development, but Claude 3.5 Sonnet’s focus on safety is a notable differentiator.
Conclusion: Which LLM is Best for Coding?
Determining the best LLM for coding: Claude 3.5, Gemini 2.0, or GPT 4o? is not straightforward. Each model has its strengths and weaknesses.
Claude 3.5 Sonnet stands out for its advanced reasoning, long-context handling, and ability to break down complex problems. It is a strong contender for complex coding tasks. GPT-4o is a versatile and efficient option, with faster response times and multimodal capabilities. It is well-suited for a wide range of coding tasks, from quick fixes to complex development. Gemini 2.0 offers a good balance, with strong multimodal capabilities and a large context window, but its cost and accessibility can be a limiting factor.
Ultimately, the choice depends on the specific needs of the developer and project. For those seeking an open-source solution, Llama 3.1 is a viable option, although it may not match the performance of the other models. Developers should also consider using tools like Bind AI Copilot to experiment with these models and determine which one best suits their needs.
It is essential to stay informed about available tools and trends, as the landscape of LLMs is constantly evolving. By leveraging the capabilities of these models, developers can refine their coding skills and embark on a journey toward more efficient coding practices.